10 无锁队列
前面两节我们介绍的比较偏理论,接下来我们会基于原子操作实现一些常见的并发数据结构,本节将要实现的目标是 —— 无锁环形队列。
环形队列
在应用无锁并发时,我们经常会用到一种数据结构——无锁队列,而无锁队列和标准库封装的队列颇有不同,它采用的是环状的队列结构。
环形队列 是一种特殊的队列数据结构,它将队列的尾端与头端连接起来,形成一个逻辑上的环形存储空间,主要好处有两个:
- 队列大小固定:因此不需要引入扩容等机制,避免了动态内存分配带来的开销
- 操作迅速:我们只需要移动头尾指针即可实现入队和出队操作,不需要频繁的析构数据
下面我们来看一个环形队列的结构:
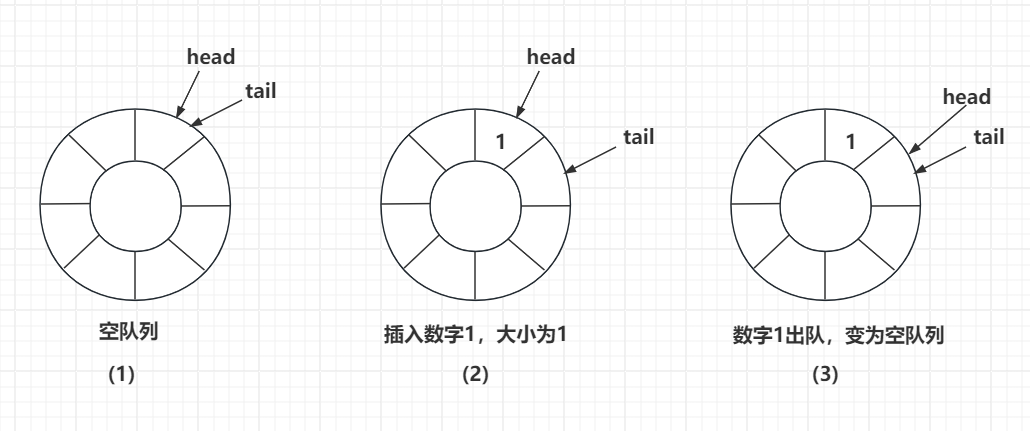
图1表示队列为空的时候,head 和 tail 交会在一起,指向同一个扇区。
图2表示当插入一个数字1后,队列大小为1,此时 tail 移动到下一个扇区,1被存储在原来 tail 指向的地方。
图3表示当我们将数字1出队后,head 向后移动一个扇区,此时 head 和 tail 指向同一个扇区,表示队列又为空了,这里也可以体现出环形队列的好处,我们并不需要析构1这个数据,因为后续的入队操作会覆盖掉它。
接着我们再次插入数据,直到队列为满,此时 tail 再走一步就会追上 head,就表示队列满了,由此我们就可以看出写代码时需要判断的地方:
- 队列为空:head == tail
- 队列为满:(tail + 1) % capacity == head
有锁版本
我们先来看一个有锁版本的环形队列:
template <typename T, size_t Capacity> class LockQueue {
public:
LockQueue() : _max_size(Capacity + 1), _data(_alloc.allocate(_max_size)) {}
~LockQueue() {
std::lock_guard<std::mutex> lock{_mutex};
// 调用析构函数
while (_size-- > 0) {
std::destroy_at(_data + _head);
_head = (_head + 1) % _max_size;
}
// 回收内存
_alloc.deallocate(_data, _max_size);
}
template <typename... Args> bool emplace(Args &&...args) {
std::lock_guard<std::mutex> lock{_mutex};
if (_size == _max_size - 1) {
return false; // 队列满
}
std::construct_at(_data + _tail, std::forward<Args>(args)...);
_tail = (_tail + 1) % _max_size;
++_size;
return true;
}
bool pop(T &value) {
std::lock_guard<std::mutex> lock{_mutex};
if (_size == 0) {
return false; // 队列空
}
value = std::move(*(_data + _head));
_head = (_head + 1) % _max_size;
--_size;
return true;
}
private:
size_t _max_size;
size_t _head{0};
size_t _tail{0};
size_t _size{0};
std::allocator<T> _alloc;
T *_data;
std::mutex _mutex;
};我们在构造时分配一块内存用于存储数据,入队时调用 construct_at 构造数据,并在析构时调用 destroy_at 析构数据并回收空间,在这个例子中,我们采用一个互斥锁来保护这个共享资源的变化,整体实现是很简单的。
无锁版本
我们尝试将有锁版本改为无锁版本,核心思路是将互斥锁改为原子,采用原子的 CAS 操作来实现,此处给出书中的一段代码,整理之后大概是这样的:
template <typename T, size_t Capacity> class UnlockQueue {
public:
UnlockQueue() : _max_size(Capacity + 1), _data(_alloc.allocate(_max_size)) {}
~UnlockQueue() {
size_t currentHead = _head.load(std::memory_order_acquire);
size_t currentTail = _tail.load(std::memory_order_acquire);
while (currentHead != currentTail) {
std::destroy_at(_data + currentHead);
currentHead = (currentHead + 1) % _max_size;
}
_alloc.deallocate(_data, _max_size);
}
template <typename... Args> bool emplace(Args &&...args) {
while (true) {
size_t currentTail = _tail.load(std::memory_order_relaxed);
size_t nextTail = (currentTail + 1) % _max_size;
if (nextTail == _head.load(std::memory_order_acquire)) {
return false; // 队列满
}
if (_tail.compare_exchange_strong(currentTail, nextTail, std::memory_order_release, std::memory_order_relaxed)) {
std::construct_at(_data + currentTail, std::forward<Args>(args)...);
return true;
}
}
}
bool pop(T &value) {
while (true) {
size_t currentHead = _head.load(std::memory_order_relaxed);
size_t nextHead = (currentHead + 1) % _max_size;
if (currentHead == _tail.load(std::memory_order_acquire)) {
return false;
}
if (_head.compare_exchange_strong(currentHead, nextHead, std::memory_order_release, std::memory_order_relaxed)) {
value = std::move(*(_data + currentHead));
std::destroy_at(_data + currentHead);
return true;
}
}
}
private:
size_t _max_size;
std::atomic<size_t> _head{0};
std::atomic<size_t> _tail{0};
std::allocator<T> _alloc;
T *_data;
};在这个版本中,我们将 _head 和 _tail 改为原子变量,并使用 compare_exchange_strong 的 CAS 操作来更新它们,确保只有一个线程能成功更新指针。
此处可以考虑一下为啥没有选择简单的内存屏障,而是利用了循环的CAS操作?是因为在高并发场景下,多个线程可能同时通过了队列满或队列空的检查,如果不使用CAS,可能会导致多个线程同时修改 _head 或 _tail,从而造成数据被重复修改。
存在的问题
乍一看这个实现没一点毛病,从单生产者单消费者、到多生产者多消费者都能正常工作,但是实际上是存在一个隐患的:
// 问题代码段
if (_tail.compare_exchange_strong(currentTail, nextTail, std::memory_order_release, std::memory_order_relaxed)) {
std::construct_at(_data + currentTail, std::forward<Args>(args)...); // 危险!
return true;
}由于我们是先更新了 _tail,再构造数据,这就导致了一个问题,消费者可能会在数据还未构造完成时就读取到这个位置的数据,从而导致读取到未初始化的数据。
因此,此种实现只适用于对象构造极快的场景,否则就会产生问题,对于更为广泛应用的实现,我们需要考虑更复杂的设计。
高性能无锁队列
为了解决上述问题,我们需要设计一个真正支持复杂对象的无锁队列,核心思路是引入 序列号机制 来确保数据完整性和可见性。
设计原理
- 序列号同步机制:队列的单个数据修改为槽,每个槽位都有一个原子序列号,用于跟踪数据状态
- 三状态序列号:
seq == pos:槽位可用于入队seq == pos + 1:槽位有数据,可出队seq == pos + Capacity:槽位已出队,可在下一轮重新入队
- 先构造后可见:先完成数据构造,再更新序列号使数据对消费者可见
实现代码
#if defined(__cpp_lib_hardware_interference_size)
constexpr size_t CACHE_LINE_SIZE = std::hardware_destructive_interference_size;
#else
constexpr size_t CACHE_LINE_SIZE = 64;
#endif
class BackOff
{
public:
void pause()
{
for (int i = 0; i < _count; i++)
{
cpu_pause();
}
if (_count < 1024)
{
_count *= 2;
}
}
void reset()
{
_count = 1;
}
private:
static void cpu_pause()
{
// x86 架构
#if defined(__x86_64__) || defined(__i386__)
__builtin_ia32_pause();
// ARM 架构
#elif defined(__arm__) || defined(__aarch64__)
__asm__ __volatile__("yield");
// 其他架构
#else
std::this_thread::yield();
#endif
}
int _count = 1;
};
template <typename T, size_t Capacity>
class SuperQueue
{
private:
// 确保容量是2的幂,便于位运算优化
static_assert((Capacity & (Capacity - 1)) == 0, "Capacity must be power of 2");
static_assert(std::is_move_constructible_v<T> || std::is_copy_constructible_v<T>,
"T must can be move or copy construction");
static_assert(std::is_nothrow_move_constructible_v<T> || std::is_nothrow_copy_constructible_v<T>,
"the copy or move shouldn't throw error");
static constexpr size_t CACHE_LINE_SIZE = 64;
struct alignas(CACHE_LINE_SIZE) Slot
{
std::atomic<size_t> _sequence{0};
alignas(T) std::array<std::byte, sizeof(T)> _storage;
T *data() noexcept
{
return std::launder(reinterpret_cast<T *>(_storage.data()));
}
};
alignas(CACHE_LINE_SIZE) std::atomic<size_t> _enqueue_pos{0};
alignas(CACHE_LINE_SIZE) std::atomic<size_t> _dequeue_pos{0};
std::array<Slot, Capacity> _buffer;
public:
SuperQueue()
{
// 初始化每个slot的序列号
for (size_t i = 0; i < Capacity; ++i)
{
_buffer[i]._sequence.store(i, std::memory_order_relaxed);
}
}
~SuperQueue()
{
// 析构剩余的元素
size_t front = _dequeue_pos.load(std::memory_order_relaxed);
size_t back = _enqueue_pos.load(std::memory_order_relaxed);
while (front != back)
{
size_t pos = front & (Capacity - 1); // 位运算取模
if (_buffer[pos]._sequence.load(std::memory_order_acquire) == front + 1)
{
std::destroy_at(_buffer[pos].data());
}
++front;
}
}
template <typename... Args>
bool emplace(Args &&...args)
{
Slot *slot;
size_t pos = _enqueue_pos.load(std::memory_order_relaxed);
BackOff backoff;
while (true)
{
slot = &_buffer[pos & (Capacity - 1)];
size_t seq = slot->_sequence.load(std::memory_order_acquire);
intptr_t diff = (intptr_t)seq - (intptr_t)pos;
if (diff == 0)
{
// 该位置可以插入,尝试占据这个位置
if (_enqueue_pos.compare_exchange_weak(pos, pos + 1, std::memory_order_relaxed))
{
break;
}
backoff.pause();
}
else if (diff < 0)
{
// 队列满
return false;
}
else
{
// 其他生产者已经占用了这个位置
pos = _enqueue_pos.load(std::memory_order_relaxed);
backoff.pause();
}
}
// 在占据的槽中构造元素
std::construct_at(slot->data(), std::forward<Args>(args)...);
// 更新序列号,使数据对消费者可见
slot->_sequence.store(pos + 1, std::memory_order_release);
return true;
}
bool pop(T &result)
{
Slot *slot;
size_t pos = _dequeue_pos.load(std::memory_order_relaxed);
BackOff backoff;
while (true)
{
slot = &_buffer[pos & (Capacity - 1)];
size_t seq = slot->_sequence.load(std::memory_order_acquire);
intptr_t diff = (intptr_t)seq - (intptr_t)(pos + 1);
if (diff == 0)
{
// 尝试更新出队位置
if (_dequeue_pos.compare_exchange_weak(pos, pos + 1, std::memory_order_relaxed))
{
break;
}
backoff.pause();
}
else if (diff < 0)
{
// 队列空
return false;
}
else
{
// 其他消费者已经占用了这个位置
pos = _dequeue_pos.load(std::memory_order_relaxed);
backoff.pause();
}
}
// 读取数据
result = std::move(*slot->data());
std::destroy_at(slot->data());
// 更新序列号,使位置对生产者可用
slot->_sequence.store(pos + Capacity, std::memory_order_release);
return true;
}
// 获取当前队列大小
[[nodiscard]] size_t size() const noexcept
{
size_t head = _enqueue_pos.load(std::memory_order_relaxed);
size_t tail = _dequeue_pos.load(std::memory_order_relaxed);
return head - tail;
}
// 检查是否为空
[[nodiscard]] bool empty() const noexcept
{
return size() == 0;
}
};设计解析
整个设计是非常巧妙的,被称为 Dmitry Vyukov's MPMC Queue,可以说是无锁编程的经典之作,下面我们来详细解析一下这个实现:
可见顺序
确保消费者只能看到完全构造好的数据,以解决之前版本的数据可见性竞争问题。
// 生产者:先构造数据,再更新序列号
std::construct_at(&slot->data, std::forward<Args>(args)...);
slot->sequence.store(pos + 1, std::memory_order_release); // 数据构造完才可见缓存行对齐优化
enqueue_pos 和 dequeue_pos 分别对齐到独立的缓存行,同时每个槽位也对齐到缓存行,从而减少伪共享。
struct alignas(64) Slot {
std::atomic<size_t> sequence{0};
T data;
};
alignas(cache_line_size) std::atomic<size_t> enqueue_pos{0};
alignas(cache_line_size) std::atomic<size_t> dequeue_pos{0};ABA问题
我们的两个索引都是始终递增的,从而避免了在预分配内存的情况下导致的 ABA 问题,且没有使用 tagger ptr 的方案,更节省性能。
解决忙等
我们在 CAS 操作不成功时都进行了 cpu.pause(),避免了大量的 CPU 空转,有利于整体程序的健壮运行。
本节代码详见此处。