14 多线程模型IOContextPool
14 多线程模型IOContextPool
在前文我们的服务器总共创建了一个ioc,不管是信号、acceptor、读写的回调都是注册到这一个ioc中,并进入会话层进行处理,所有的设计都是在我们的主线程中,比较类似于reactor的单reactor单线程模型。
asio的多线程模型总共有两种:
创建多个线程,每个线程跑一个ioc,客户端发起连接后绑定到其中一个线程的ioc,由当前线程回调。
依旧是主线程一个ioc,不过在接受到连接时把连接投递到子线程处理。
哎,是不是非常熟悉,前者就类似于 多reactor多线程模型,后者类似于 单reactor多线程模型,是线上也是非常类似的,本节我们先来介绍第一种多线程模型。
设计思路
我们希望程序开始时初始化一个 IOContextPool,里面跑着好多线程,每个线程都有一个ioc.run(),当客户端发起连接后,我们取出一个线程的ioc,客户端的session就基于此ioc创建,之后所有的读写操作都由此ioc调度,大概是如下图所示:
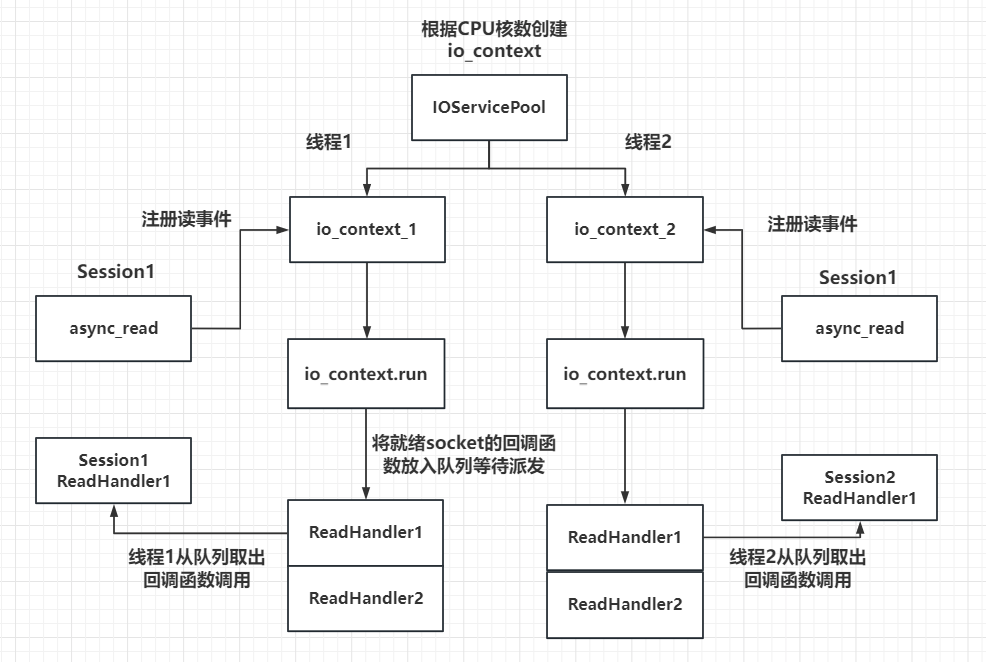
需要注意的是,多个连接可能在同一个线程也可能在不同的线程,我们此处来分析一下并发上的安全:
每一个io_context跑在不同的线程里,所以同一个socket会被注册在同一个io_context里,它的回调函数也会被单独的一个线程回调,那么对于同一个socket,他的回调函数每次触发都是在同一个线程里,就不会有线程安全问题,网络io层面上的并发是线程安全的。
但是对于不同的socket,回调函数的触发可能是同一个线程(两个socket被分配到同一个io_context),也可能不是同一个线程(两个socket被分配到不同的io_context里)。所以如果两个socket对应的上层逻辑处理,如果有交互或者访问共享区,会存在线程安全问题。比如socket1代表玩家1,socket2代表玩家2,玩家1和玩家2在逻辑层存在交互,比如两个玩家都在做工会任务,他们属于同一个工会,工会积分的增加就是共享区的数据,需要保证线程安全。可以通过加锁或者逻辑队列的方式解决安全问题,我们目前采取了后者。
多线程相比单线程,极大的提高了并发能力,因为单线程仅有一个io_context服务用来监听读写事件,就绪后回调函数在一个线程里串行调用, 如果一个回调函数的调用时间较长肯定会影响后续的函数调用,毕竟是串行调用。而采用多线程方式,可以在一定程度上减少前一个逻辑调用影响下一个调用的情况,比如两个socket被部署到不同的iocontext上,各个线程自己回调,但是当两个socket部署到同一个iocontext上时仍然存在调用时间影响的问题。不过我们已经通过逻辑队列的方式将网络线程和逻辑线程解耦合了,不会出现前一个调用时间影响下一个回调触发的问题。
代码实现
那实现上就很简单了,只需要初始化一个池子,对外暴露获取ioc的方法,当有一个连接过来时,取出一个ioc进行调度即可,此处依旧是 单例 + pimpl 实现,在逻辑层中已经这么写过,此处可以直接看一下代码:
class CORE_EXPORT IOPool final : public global::Singleton<IOPool> {
friend class global::Singleton<IOPool>;
private:
IOPool(std::size_t size = std::thread::hardware_concurrency());
public:
~IOPool();
// round-robin 获取一个 io_context
boost::asio::io_context &getIocontext();
private:
struct _impl;
std::unique_ptr<_impl> _pimpl;
};具体的实现代码:
struct IOPool::_impl {
std::vector<boost::asio::io_context> _ioContexts;
std::vector<boost::asio::executor_work_guard<boost::asio::io_context::executor_type>> _workGuards;
std::vector<std::jthread> _threads;
std::atomic<std::size_t> _nextIndex{0};
_impl(std::size_t size) : _ioContexts(size) {
// 创建各个ioc的work_guard,防止提早退出
_workGuards.reserve(size);
for (auto &ioc : _ioContexts) {
_workGuards.emplace_back(boost::asio::make_work_guard(ioc));
}
// 创建各个线程,每个线程自己跑一个ioc
_threads.reserve(size);
for (auto &ioc : _ioContexts) {
_threads.emplace_back([&ioc]() -> void {
ioc.run();
});
}
}
};
IOPool::IOPool(std::size_t size) : _pimpl(std::make_unique<_impl>(size)) { }
IOPool::~IOPool() {}
boost::asio::io_context &IOPool::getIocontext() {
const std::size_t poolSize = _pimpl->_ioContexts.size();
const std::size_t index = _pimpl->_nextIndex.fetch_add(1, std::memory_order_relaxed) % poolSize;
return _pimpl->_ioContexts[index];
}这里我们需要看一下这个 work_guard,因为常规的ioc调用run时如果没有事件就会退出,引入work_guard可以阻塞ioc,直到work_guard销毁。
主线程跑一个ioc,负责捕获退出信号和acceptor,接收到连接后由各个子线程进行业务处理(read -> 业务 -> send),此时豁然开朗,这不就是多 Reactor 多线程的网络并发模型嘛,这下看懂了吧。
修改server
那么在Server.cc中,我们接受到连接时取出一个ioc进行构造即可:
void Server::start_accept() {
auto &ioc = ioPool.getIocontext();
auto new_sess = std::make_shared<Session>(ioc, this);
···· 其余代码
}测试服务器
此处我修改了客户端,客户端会创建100个线程,每个线程会进行500次读写,也就是说总共100k个包,笔者的电脑是16核的cpu,测试下来共消耗 1247ms,表现相当的不错。
总结
本节我们通过实现一个 IOPool,在程序启动时创建多个线程,每个线程都运行一个独立的 io_context,从而构建了一种多线程网络模型。
本节的核心是:通过 round-robin 方式将新连接分发到不同的 io_context 实例上,实现了类似于多 Reactor 多线程的网络并发模型,从而显著提升了服务器的并发处理能力。
本节代码详见此处。